


Continuous Delivery mit GitLab CI und Ansible (Teil 2)
Wir haben leider eine ganze Weile gebraucht, um die Fortsetzung unseres ersten Teils der Serie zu liefern. Es gab viel gute Arbeit zu verrichten für unsere Kunden. Aber hier ist er nun endlich.
Während Teil 1 das große Ganze im Blick hatte und beschrieb, wie Ansible in Kombination mit Gitlab CI zum Ausliefern von Software in verschiedene Umgebungen genutzt werden kann, wird sich dieser Artikel stärker darauf fokussieren, die Gitlab Artefakte mit Hilfe von Ansible zu installieren. Konkret schauen wir uns eine vollständige Pipeline an, die schlussendlich unsere Spring Boot-Applikation in einer Staging-Umgebung installieren wird.
Wir fangen an, einen Überblick über die IT-Landschaft zu geben, mit der wir es hier zu tun haben. Das sollte auch die Erinnerungen an den ersten Teil auffrischen:
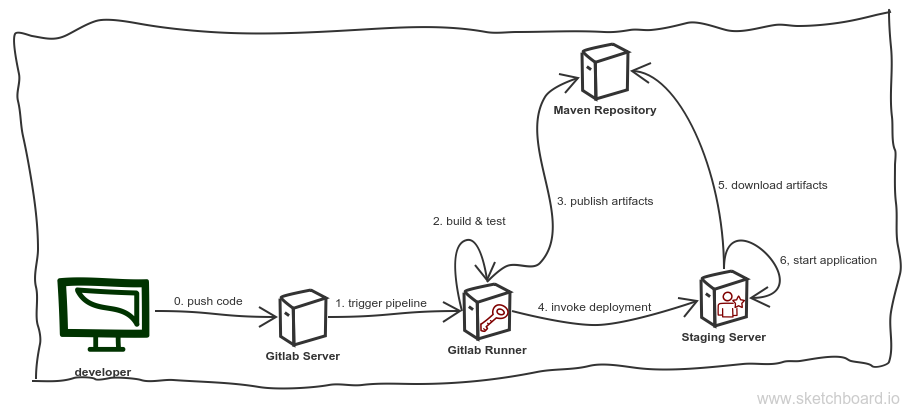
Einige Teile dieser Skizze sollten uns bekannt vorkommen. Wir haben den Entwickler, der Code mit Hilfe von Git pusht auf einen Gitlab-Server (Schritt 0), welcher seinerseits die Pipeline anstößt (Schritt 1). Die Pipeline setzt alles weitere in Bewegung, ihre Jobs sind verantwortlich dafür, die Applikation zu bauen und zu testen (Schritt 2), die gebauten Artefakte in einem Maven Repository zur Verfügung zu stellen (Schritt 3), das Installieren via Ansible auf unserem Staging-Server anzustoßen (Schritt 4), wobei das Repository aus Schritt 3 genutzt wird, um die Artefakte herunterzuladen (Schritt 5). Zu guter Letzt startet sie die Applikation neu (Schritt 6).
Im Folgenden schauen wir uns die einzelnen Jobs der Pipeline genauer an. Wie wir gelernt haben, ist eine Pipeline nichts weiter als eine Reihe von Jobs, die Gitlab für uns ausführen wird. Der erste Job in unserer Pipeline ist, die Spring Boot-Applikation zu bauen und zu testen.
Die Pipeline für ein Code-Repository wird in einer Datei definiert,
die .gitlab-ci.yml heißt. So sieht eine Definition der Schritte 2
und 3 unserer Pipeline aus:
variables:
# Dies unterdrückt ein erneutes Herunterladen von Abhängigkeiten und Plugins und verhindert das Anzeigen von Upload-Nachrichten im Log.
# `showDateTime` wird die vergangene Zeit in Millisekunden anzeigen. Es muss `--batch-mode` mitgegeben werden, damit das funktioniert.
MAVEN_OPTS: "-Dorg.slf4j.simpleLogger.log.org.apache.maven.cli.transfer.Slf4jMavenTransferListener=WARN -Dorg.slf4j.simpleLogger.showDateTime=true -Djava.awt.headless=true"
# Seit Maven 3.3.0 kann diesen Option alternativ auch in `.mvn/maven.config` definiert werden. Damit würde dieselbe Konfiguration genutzt werden,
# wenn dies von der Kommandozeile aus ausgeführt würde.
# `installAtEnd` und `deployAtEnd` funktionieren nur mit aktuellen Versionen der entsprechenden Erweiteurngen.
MAVEN_CLI_OPTS: "--batch-mode --errors --fail-at-end --show-version -DinstallAtEnd=true -DdeployAtEnd=true"
POSTGRES_DB: our_test_project_database
POSTGRES_USER: our_test_project_user
POSTGRES_PASSWORD: our_test_project_password
cache:
paths:
- /root/.m2/repository
stages:
- build
- test
- release
validate:jdk8:
stage: build
script:
- 'mvn $MAVEN_CLI_OPTS test-compile'
image: maven:3.5.0-jdk-8
deploy:jdk8:
stage: test
services:
- postgres:9.6
script:
- 'mvn --settings settings.xml $MAVEN_CLI_OPTS -Dspring.profiles.active=gitlab deploy'
image: maven:3.5.0-jdk-8
release_staging:
stage: release
image: williamyeh/ansible:centos7
only:
- master
tags:
- ansible
script:
- 'ansible-playbook -i staging deploy.yml'
Gehen wir dies Schritt für Schritt durch. Zu Beginn deklarieren wir einige Variablen, die wir später gebrauchen können:
# Dies unterdrückt ein erneutes Herunterladen von Abhängigkeiten und Plugins und verhindert das Anzeigen von Upload-Nachrichten im Log.
# `showDateTime` wird die vergangene Zeit in Millisekunden anzeigen. Es muss `--batch-mode` mitgegeben werden, damit das funktioniert.
MAVEN_OPTS: "-Dorg.slf4j.simpleLogger.log.org.apache.maven.cli.transfer.Slf4jMavenTransferListener=WARN -Dorg.slf4j.simpleLogger.showDateTime=true -Djava.awt.headless=true"
# Seit Maven 3.3.0 kann diesen Option alternativ auch in `.mvn/maven.config` definiert werden. Damit würde dieselbe Konfiguration genutzt werden,
# wenn dies von der Kommandozeile aus ausgeführt würde.
# `installAtEnd` und `deployAtEnd` funktionieren nur mit aktuellen Versionen der entsprechenden Erweiteurngen.
MAVEN_CLI_OPTS: "--batch-mode --errors --fail-at-end --show-version -DinstallAtEnd=true -DdeployAtEnd=true"
POSTGRES_DB: our_test_project_database
POSTGRES_USER: our_test_project_user
POSTGRES_PASSWORD: our_test_project_password
Als nächstes deklarieren wir eine Liste von Pfaden (tatsächlich ist es in diesem Fall nur einer), die zwischen den einzelnen Jobs aufbewahrt werden soll. Wir wollen nicht, dass Maven alle Abhängigkeiten wieder und wieder herunterlädt.
cache:
paths:
- /root/.m2/repository
Nachdem das erledigt ist, deklarieren wir drei sogenannte
Stages. Ein Stage (auf
Deutsch vielleicht am besten mit Phase übersetzt) kann genutzt
werden, verschiedene Jobs zu gruppieren. Jobs, die zur
gleichen Phase gehören, werden parallel ausgeführt. Unsere drei
Stages sind build, test und release:
stages:
- build
- test
- release
Es gibt noch einen weiteren wichtigen Aspekt die definierten Phasen
betreffend: Jobs, die zu einer bestimmten Phase gehören, werden nur
dann ausgeführt, wenn die Jobs der vorhergehenden Phase erfolgreich
durchgeführt werden konnten. Das würde in unserem Fall bedeuten,
dass die Jobs der test-Phase nur dann getriggert würden, wenn die
Jobs der build-Phase alle erfolgreich ausgeführt wurden. Das ist
sehr nützlich.
So sieht diese Sequenz der Phasen der Pipeline in Gitlab aus:

Nachdem die Grundlagen gelegt wurden, können wir uns dem Definieren
der Jobs widmen, die Gitlab für uns ausführen soll. Der erste Job
wird validate:jdk8 genannt:
validate:jdk8:
stage: build
script:
- 'mvn $MAVEN_CLI_OPTS test-compile'
image: maven:3.5.0-jdk-8
Dieser Job gehört zur build-Stage und hat die folgenden zwei
Merkmale: (1) Es führt mvn test-compile mit den $MVN_CLI_OPTS
aus, die wir oben in dem variables-Abschnitt definiert haben
aus. Maven wird dann die Ressourcen verarbeiten, die Applikation und
die dazugehörigen Tests kompilieren. (2) Es tut all dies innerhalb
eines
Docker-Images, in diesem Fall des maven:3.5.0-jdk-8-Images, welches auf
Docker Hub gefunden werden kann.
Der nächste Job ist deploy:jdk8. Die Definition dieses Jobs sieht so aus:
deploy:jdk8:
stage: test
services:
- postgres:9.6
script:
- 'mvn --settings settings.xml $MAVEN_CLI_OPTS -Dspring.profiles.active=gitlab deploy'
image: maven:3.5.0-jdk-8
Dies ist ein Job der test-Phase. Es führt erneut Maven aus und
nutzt das gleiche Docker-Image wie der
validate:djk8-Job. Zusätzlich benötigt dieser Job noch eine
laufende PostgreSQL-Datenbank. Es nutzt
die Variablen, die wir oben im variables-Abschnitt gesetzt
haben. Ja, so einfach ist das. Die Datenbank, die Gitlab uns dann zur
Nutzung bereitstellt, ist erreichbar unter dem Hostnamen
postgres. Mit Hilfe eines
Spring-Profils
, das wir für diesen Zweck erzeugt haben, passen wir die
Verbindungs-URL für JDBC entsprechend an.
Der letzte Job ist der release-Job auf den wir alle gewartet
haben. Schauen wir uns ihn noch einmal genauer an:
release_staging:
stage: release
image: williamyeh/ansible:centos7
only:
- master
tags:
- ansible
script:
- 'ansible-playbook -i staging deploy.yml'
In diesem Fall installieren wir unsere Spring Boot-Applikation in
einer Staging-Umgebung. Dieser Job ist Teil der release-Phase und
wird nur dann ausgeführt, wenn der master-Branch aktualisiert
wird. (Dies gilt nicht für die Jobs, die wir uns zuvor angeschaut
haben, diese werden bei jedem gepushten Gitcommit ausgeführt.)
Eine Anmerkung: Es ist möglich, die Applikation nicht automatisch zu
installieren oder zu aktualisieren, jedes Mal wenn der master-Branch
aktualisiert wurde. Um zu erreichen, dass die Applikation nur durch manuelles Auslösen
installiert oder aktualisiert wird, kann die Job-Definition um folgendes
ergänzt werden: when: manual. Im Anschluss daran kann durch einen Klick auf
den entsprechenden Button in Gitlab das Deployment ausgelöst werden. (Siehe
"Play-Button" unten.) Die angepasste Job-Definition sähe dann so aus:
release_staging:
stage: release
image: williamyeh/ansible:centos7
only:
- master
when: manual
tags:
- ansible
script:
- 'ansible-playbook -i staging deploy.yml'

In beiden Fällen tut dieser Job genau eine Sache: Es führt ein Ansible-Playbook aus:
script:
- 'ansible-playbook -i staging deploy.yml'
Eine anderes Detail, dass wir noch beachten sollten, ist das
tags-Element dieser Job-Beschreibung. Ein tag dient der Auswahl des
GitLab-Runners fuer diesen Job. Jeder Runner kann einen oder mehrere Tags haben. Dieser Job hat denansible-Tag. Das bedeutet, dass der Gitlab-Runner für diesen Tag hier ausgewählt wird.
Das Docker-Image, dass wir hier verwenden, ist ein nicht-offizielles,
aber sehr gutes Dockerimage mit CentOS 7, welches Ansible für uns
bereitstellt. Es führt, wie oben schon besprochen, das Playbook
aus.
Das Playbook ist das nächste, das wir uns genauer ansehen sollten:
---
- hosts: web
become: true
tasks:
- name: Install python setuptools
apt: name=python-setuptools state=present
- name: Install pip
easy_install: name=pip state=present
- name: Install lxml
pip: name=lxml
- name: Download latest snapshot
maven_artifact:
group_id: our.springboot.application
artifact_id: our_springboot_artifact_id
repository_url: http://our_springboot_server.bevuta.com:8080/artifactory/our_springboot_application/
username: our_springboot_user
password: our_springboot_password
dest: /home/our/springboot_application.jar
- name: Copy systemd unit file
copy: src=our_springboot_application.service dest=/etc/systemd/system/our_springboot_application.service
- name: Start web interface
systemd:
state: restarted
name: our_springboot_application
enabled: yes
daemon_reload: yes
Der erste Teil ist recht einfach: Dieses Playbook definiert Aufgaben
für alle Hosts, die zur Gruppe web gehören. Und ja, Ansible soll
auf den Zielsystemen als Root arbeiten dürfen, dafuer setzen wir become:
true.
Der Rest definiert, was Ansible für uns erledigen soll. Zu Beginn
installieren wir einige Python-Werkzeuge, die Ansible benötigt, um
die maven_artifact-Aufgabe zu erledigen.
- name: Install python setuptools
apt: name=python-setuptools state=present
- name: Install pip
easy_install: name=pip state=present
- name: Install lxml
pip: name=lxml
Das ist leider wenig elegant. Vielleicht kennen Sie einen besseren Weg, das zu tun? Lasst es uns wissen.
Nachdem wir die Zielsysteme vorbereitet haben, laden wir unser Artefakt herunter, das Gitlab für uns in Schritt 2 gebaut und in das Maven Repository hochgeladen hat:
- name: Download latest snapshot
maven_artifact:
group_id: our.springboot.application
artifact_id: our_springboot_artifact_id
repository_url: http://our_springboot_server.bevuta.com:8080/artifactory/our_springboot_application/
username: our_springboot_user
password: our_springboot_password
dest: /home/our/springboot_application.jar
Zu guter Letzt (und endlich) starten wir unsere Spring
Boot-Applikation automatisch, in dem wir eine
systemd-Unit
aktivieren, die Ansible für uns auf Zielsystemen angelegt hat:
- name: Copy systemd unit file
copy: src=our_springboot_application.service dest=/etc/systemd/system/our_springboot_application.service
- name: Start web interface
systemd:
state: restarted
name: our_springboot_application
enabled: yes
daemon_reload: yes
Eine Unit-Datei beschreibt eine sogenannte "systemd unit". Was genau das ist? Schauen wir mal in die "man page" davon: Eine "systemd"-Unit ist "a service, a socket, a device, a mount point, an automount point, a swap file or partition, a start-up target, a watched file system path …" ( man/systemd.unit).
In unserem Falle erzeugt Ansible eine Unit-Datei, die systemd wissen lässt, wie es unsere Spring Boot-Applikation behandeln soll, nämlich, dafür zu sorgen, dass diese beim Starten des Systems ebenfalls gestartet wird.
Und damit wären wir dann am Ende angekommen. Unsere Spring Boot-Applikation wurde gebaut, getestet, in ein Maven-Repository hochgeladen, daraus auf Zielsysteme heruntergeladen und gestartet. All dies automatisiert.